开云app官方最新版下载 60个量子比特顶百万倍内存: 量子机器学习找到新的阻碍口

4 月 8 日,一支由加州理工学院、谷歌量子 AI、MIT 和初创公司 Oratomic 组成的皆集团队在预印本平台 arXiv 发布论文,宣称评释注解了一个遥远悬而未决的命题:微型量子计较机不错在处理大领域经典数据的(部分)机器学习任务中,以指数级更少的内存超越经典计较机。
推断团队在电影指摘情怀分析和单细胞 RNA 测序两个真实数据集上考证了这一上风。用不到 60 个逻辑量子比特,量子算法的内存浪费就比经典法式低了四到六个数目级。

图丨关系论文(开始:arXiv)
量子机器学习这个领域依然阻挠了二十年,但一直没能已毕早期的精深应许。领先那批算法堪称能加快线性代数运算,自后被一系列“去量子化”责任评释注解经典计较机用秘要的随即采样也能作念到;变重量子电路一度被交付厚望,却在考研中平日撞上“贫寒高原”,梯度隐匿得找都找不到。
但这些鬈曲背后有一个更根底的问题:简直通盘宣称有量子加快的算法,都假定数据依然以量子态的面目存在于机器中。现实天下的数据偏巧是经典的,比如一条条电影指摘、一张张 CT 影像、一转行基因抒发数据……怎样把这些东西高效地“喂”给量子计较机,一直是个没东说念主能绕以前的坎。
量子随即存取存储器(Quantum Random Access Memory,QRAM)曾被视为这个问题的终极解法。
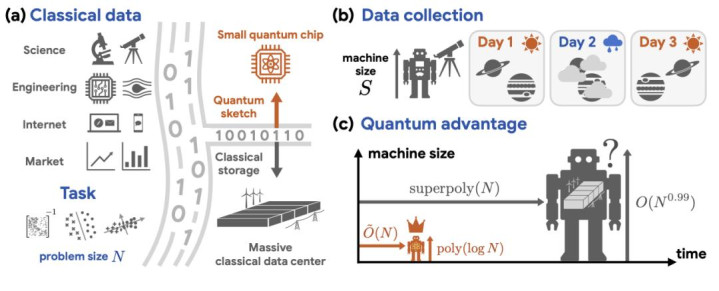
图丨处理海量经典数据时的量子上风(开始:arXiv)
这种开辟表面上能让量子计较机像查字典一样,在访佛态中同期拜谒多数经典数据。但 QRAM 于今停留在纸面上,督察它所需的关系拜谒对硬件要求极为刻薄。2024 年发表在 npj Quantum Information 上的一项推断从因果律和相对论旨趣动身推导 QRAM 的物理上限,论断相称悲不雅:要让 QRAM 达到实用领域,所需的硬件复杂度本人就会吃掉量子上风带来的收益。
更无语的是,用来督察 QRAM 运行的经典适度系统经常实足强劲,不错平直处理本来策划交给量子计较机的问题。到 2019 年前后,业界初始隆重想考一个问题:在处理来自宏不雅天下的经典数据时,量子计较机到底还能不可展现出任何上风?
新论文的阻碍在于澈底绕开了 QRAM。推断团队建议了一套名为“量子预言机速写”(Quantum Oracle Sketching)的算法框架,中枢想路迥殊地肤浅:把数据行为流来处理。每不雅察到一条经典数据样本,就对量子系统施加一个经心假想的小旋转操作,然后立即丢弃这条数据。
跟着越来越多的数据流过,这些小旋转渐渐积聚,最终在量子系统中构建出一个实足精准的“预言机”近似,这个预言机不错被后续的量子算法调用,就大要数据依然以量子态的面目存在一样。
论文第一作家、加州理工学院博士生赵海萌在 Quantum Frontiers 博客上解释了这个办法的直观开始。传统想路是先把所稀奇据存下来,再让量子计较机去拜谒;流式处理的逻辑竣工不同,数据来一条处理一条,处理完就丢,量子系统的气象本人便是对数据的压缩默示。这有点像经典的流式算法和在线学习,只不外量子版块能把信息压缩到指数级更小的空间里。

图丨赵海萌(开始:https://hmzhao.me/)
不外这种法式亦然有代价的。论文评释注解,用经典数据样本构建量子预言机需要付出“平方代价”,若是你想调用预言机 Q 次,就需要浪费轻松 Q² 条数据样本。这个代价源于量子力学的玻恩限定,量子振幅和经典概率之间的平方关系是绑死的。推断团队同期评释注解了这个平方代价是最优的,不可能再裁减。
推断团队选了两个数据集作念考证:IMDb 电影指摘数据集,任务是判断一条指摘是正面如故负面;单细胞 RNA 测序数据,任务是把高维的基因抒发数据投影到低维空间以折柳不同类型的细胞。实验相比了四种法式:量子预言机速写、基于 QRAM 的量子算法、经典疏淡矩阵算法、经典流式算法。为了公说念相比,推断者斡旋用“基本存储单位”来量度内存浪费,量子算法用逻辑量子比特数,经典算法用浮点数个数。
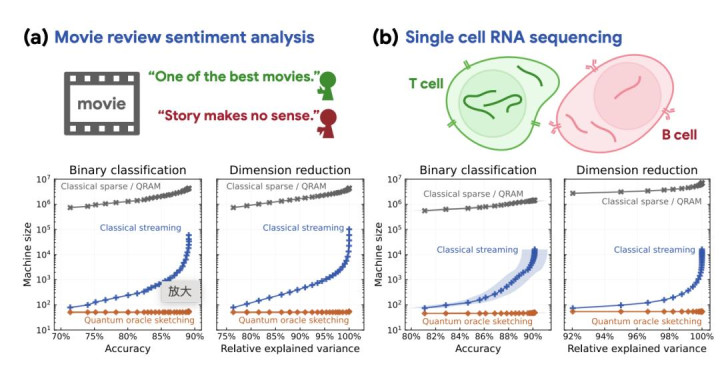
图丨数值实考评释注解了在真实天下数据集上存在指数级的量子上风。(开始:arXiv)
效率相称惊东说念主。要达到同等的瞻望性能,开云app官方最新版下载量子预言机速写只需要不到 60 个逻辑量子比特,而经典法式需要的内存高出四到六个数目级。更挑升义的是,当迟缓闭幕内存预算时,量子算法的性能简直不受影响,而经典算法的阐扬急剧下跌。
赵海萌在博客中打了个譬如:300 个逻辑量子比特的量子处理器,在存储智商上不错超越一台由可不雅测寰宇中每一个原子组成的经典计较机。天然,要的确看到这种戏剧性的对比,还需要寰宇级别的数据集和处理时分。
四到六个数目级的差距天然惊东说念主,但更值得关注的是这种上风的本质。
论文的中枢定理修复了机器大小与查询复杂度之间的根底关系:关于求解线性系统、分类、降维这些常见任务,一台多对数大小的量子机器不错在近线性时天职完成,而任何内存小于问题领域 0.99 次方的经典机器都作念不到,即便给它超多项式的样本和时分也不行。
更枢纽的是,这种上风是“信息论层面的”和“无条目的”,不依赖任何计较复杂性料想,只是依赖量子力学本人的正确性。换句话说,即便异日有东说念主评释注解经典计较机和量子计较机在多项式时天职能处理雷同的问题,这里评释注解的上风依然确立。
这和之前展示的“量子优胜性”实验有本质区别。2019 年谷歌用 Sycamore 处理器完成的随即电路采样任务评释注解的是计较速率上的上风,况兼阿谁任务本人莫得什么本质用途。这一次,上风体当今内存而非速率,况兼任务(分类和降维)是机器学习中最基础、诓骗最广的操作。
John Preskill 在论文发布本日发推说:“咱们的论文评释注解,量子机器不错用指数级更少的内存处理常见的机器学习任务。要把这个表面滚动为实施还需要多数责任。但因为当代 AI 经常受限于内存不及,这个发现增强了咱们的信心:量子 AI 最终能对日常生计产生无为影响。”
天然需要强调的是,这项推断咫尺仍是表面评释注解加数值模拟,尚未在真实量子硬件上考证。论文中的“60 个逻辑量子比特”是个容易激勉歪曲的数字。逻辑量子比特是过程量子纠错编码的、受到保护的量子比特,和刻下噪声中等领域量子开辟上的物理量子比特竣工不是一趟事。要实现一个逻辑量子比特,可能需要数百致使上千个物理量子比特加上配套的纠错电路。
谷歌在 2024 年底发表于《Nature》的推断中刚刚初度展示了纠错性能随编码领域增大而栽培的“阈值以下”操作,从那一步到能褂讪运行 60 个逻辑量子比特,中间还有相称长的路。
还有一个很多东说念主都关怀的问题可能是:这对大讲话模子来说灵验吗?论文处理的是分类和降维这类“判别式”任务,而大讲话模子是生成式的。赵海萌在博客中坦承,咫尺的效率“并扞拒直意味着对大讲话模子等当代生成式 AI 的即时遵守”。
但他相比乐不雅地默示:“我有一种浓烈的嗅觉,咱们正处于一个与传统机器学习期间惊东说念主相似的历史节点——阿谁维持向量机和随即丛林主导的期间,阿谁咱们依赖严格统计分析因为缺少大领域启发式探索所需计较资源的期间,阿谁最终滋长出深度学习和 AI 创新的期间。”
量子计较社区一直被一个问题困扰:除了破解密码和模拟量子系统,量子计较机到底还能用来干什么?这项推断给出了一个部分谜底。不是因为机器学习任务本人有什么量子结构,而是因为量子态的指数级抒发智商不错用来十分压缩对经典数据的默示,前提是你得找到相宜的法式把数据“流”进去。
Preskill 在 2012 年建议“量子优胜性”倡导时曾征引费曼的名言:“天然不是经典的,活该的,若是你想模拟天然,你最佳把它作念成量子力学的。”这篇论文的作家们在博客中整活回转了这句话:“咱们生计在一个本质上是经典的天下里开云app官方最新版下载,活该的,也许经典计较机和 AI 对咱们的大多数问题依然够用了。”他们的论文评释注解,这个“也许”背面还有很大的商榷空间。
开云体育(中国)官方网站 备案号:
备案号: